YOLOv5에서 100×100 pixel 이미지로 학습시키면 128로 변환된다. 오류 메세지를 보면 32배수를 이어야 한다고 한다. OpenCV에서 zero-padding은 다음과 같이 해결한다. 순서는, 위-아래-왼쪽-오른쪽이다.
cv2.copyMakeBorder(img, 14, 14, 14, 14, cv2.BORDER_CONSTANT, value=[0,0,0])
YOLOv5에서 100×100 pixel 이미지로 학습시키면 128로 변환된다. 오류 메세지를 보면 32배수를 이어야 한다고 한다. OpenCV에서 zero-padding은 다음과 같이 해결한다. 순서는, 위-아래-왼쪽-오른쪽이다.
cv2.copyMakeBorder(img, 14, 14, 14, 14, cv2.BORDER_CONSTANT, value=[0,0,0])

지난 주말에 학습시킨 사람/차를 학습 시킨 모델을 이용하여 새로운 사진을 평가해 보았다. 이 사진은 오늘 BBC에 실린 사진이니 모델은 처음 본 사진이다.
잘 동작하는 것을 볼 수 있다.
YOLOv5 학습과 관련되어 많은 도움이 된 곳의 링크는 다음이다.
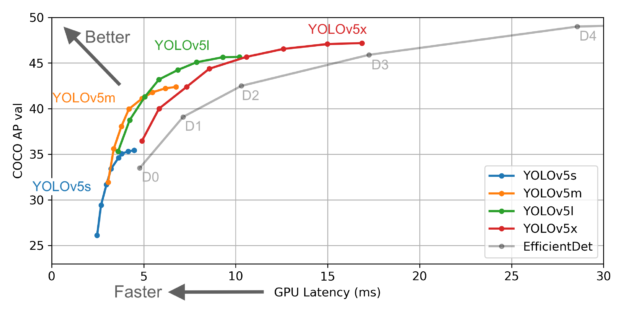
YOLOv5는 모델의 크기에 따라서 s, m, l, x 4가지가 있다. 큰 모델을 이용할 수록 검출을 잘 하는 것으로 알려져 있으나, 반대 급부로 학습에 더 많은 시간이 소요되고, 속도가 느리다고 한다. 속도가 중요한 문제가 되는 이유는 실시간 검출을 하는 경우가 많기 때문이다. 초당 많은 이미지를 평가할 수 있을 수록 실전에서는 유용해지기 때문이다. 운전을 예로 들면 초당 1회 검출하는 것보다는 10번이, 10번 보다는 30번이 훨씬 더 안전하게 운전이 가능할 것으로 예상되는 것과 같다.
어제 처음 학습을 시킬 때에는 s를 이용했는데, 오늘 시간이 조금 남아서 일단 x로 다시 학습을 시키도록 하고 집으로 왔다. 배치 크기를 거의 10% 수준으로 낮춰야 하는 문제가 있기는 하지만, 실제로 현저한 분석 시간의 저하는 없는 것 같다.
Jupyter Notebook에서 업그레이드한 것이 Jupyter Lab 이라고 하길래 설치해 보려고 한다. pip를 이용해서 간단하게 설치할 수 있다.
pip3 install jupyterlab원격 접속을 위해서 우선 환경 설정 파일을 만든다. notebook과 동일하게 하면 된다.
jupyter lab --generate-config비밀번호 키를 생성한다. Python에서 다음의 명령어를 입력하고 나오는 결과물을 복사해 둔다.
from jupyter_server.auth import passwd; passwd()~/.jupyter/jupyter_lab_config.py를 수정한다. 다음의 부분을 찾아서 수정해 주면 된다.
c.ServerApp.password = 'sha1: ....'
c.ServerApp.root_dir = ' '