주의: 통계 비전공자의 글이므로 용어의 대한 설명이 부적절할 수 있음.
Bootstrapping.
여러 곳에서 사용되는 단어이자 개념인듯하다.
역시 통계에서도 사용된다.
인터넷을 통한 검색에 의하면
표본크기의 한계를 극복하고 모수통계기법의 비현실성을 극복하기 위한
대안으로 널리 사용되는 방법이라고 한다.
나의 실험에 사용한 하나의 실험 자료가 있고, 이 자료에는 n개의 샘플이 있다고 하자.
그 동안의 통계는 이 실험자료는 모집단에서 추출한 자료로 간주를 하고,
그에 따른 통계적인 분석을 하는 것이 일반적이다.
Bootstrapping 방법에서는 나의 실험자료를 하나의 모집단이라고 가정한다.
이 자료에서 임의로 자료를 추출해서 다른 자료를 만들어가는데,
추출 과정에서 중복 추출이 가능하다(복구 replacement 라고도 하는 듯).
이렇게 추출을 하는데 원래 모집단과 같은 숫자인 n개의 자료를 추출한다.
이렇게 만든 표본을 bootstrapping sample 이라고 한다.
중복 추출이 가능하기 때문에
원자료와 똑같은 표본을 만들 수도 있고,
빈도는 낮을지라도 하나의 자료로만 구성된 sample 도 만들어 질 수 있다.
이렇게 표본을 만들어서 그 결과를 바탕으로 통계 분석을 시행하고,
그 분석을 바탕으로 하여 원자료에서는 어떻게 나올지에 대하여 추론하는 것이다.
표본을 만드는 방식에는 가능한 모든 경우를 다 시행하는 경우 (exact version .?)
그리고 임의로 만드는 방법이 있다.
통상적으로 사용하는 방식은 임의적으로 만들어내는 방식이다.
이렇게 반복되는 계산을 바탕으로 하여 원래의 값을 추정해 나가는 방식의
논리적인 전개 방법을 Monte Carlo Algorithm 이라고 하는 듯 함.
따라서, 고려해야 하는 부분은 다음과 같다.
1. 임의로 추출하는 과정이 정말로 임의적(random)일 것이냐 하는 것
2. 그러면 몇 번이나 반복을 해야하는가(k, B 등으로 표현됨)
임의성(Randomness)에 관한 것은
설명을 듣는다고 해서 내가 이해할 수 있는 것이 아니다.
임의의 수는 R에서 기본적으로 Mersenne-Twister 방식에 의해서 만들어진다고 한다.
이 MT 방식은 암호학적으로 안전한 방식은 아니지만,
통상적인 통계 방법에 적용하기에는 충분하다고 한다.
k의 범위에 대해서는 실험의 성격에 따라서 달라진다고 하는데,
통상적인 실험의 경우라면 1,000번이면 충분하다고 한다.
금융쪽에서는 100만번 정도 반복한다고 한다.
물론 요즘은 컴퓨터 계산속도가 빠르고,
일반적인 의학 연구의 샘플의 크기가 큰 편이 아니기 때문에
k를 좀 늘려도 되기는 하지만,
통계적으로 얼마나 의미가 있는지는 모른다.
나의 샘플에서는 100번, 1,000번, 10,000번을 시행하였을 경우,
분포 곡선은 크게 차이 나지 않는 것을 확인하였다.
약간 차이가 있다면 반복횟수가 증가하면 분포 곡선이 더 미끈해지는 것 같다고나 할까..
따라서, 반복 횟수를 10,000번 이상 늘릴 필요는 없으며,
다른 아이디어를 적용하는 것이 시간을 더 효율적으로 사용할 수 있을 것으로 생각된다.
이러한 기본 컨셉을 확인한 후에 bootstrapping 방법을 응용하여
Kaplan-Meier survival analysis 에서 p-value 의 분포를 확인해 보기로 하였다.
R에서 기본으로 제공하는 함수 중
sample 이라는 함수가 random resampling 을 해주며,
replace=TRUE 옵션을 통해서 replace 여부를 설정해 줄 수 있다.
이 함수를 이용해서 원래 자료 중에서 몇 번째 자료를
추출하여 bootstrapping sample 을 만들지 정할 수 있다.
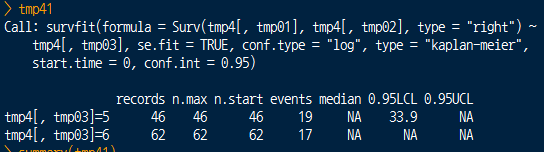
survdiff 함수를 통한 생존의 차이를 평가하는 함수는
p.value 를 직접 추출할 수 없기 때문에 간접적으로 추출하여
직접 계산을 해주어야 한다고 한다.
인터넷을 통하여 방법을 확인할 수 있었다.
그 동안의 R 삽질로 배운 것이 있다면,
반복 구문에서 사용되거나 계산하는 값들은 한 번 실행이 끝날 때마다
계속 지우고 다시 만들어야
문제가 생겼을 때 어디쯤에서 잘못 했는지 확인하기가 쉽다.
bstr.k <- 10000; 몇 번 반복할지를 미리 지정해주고..
bstr.matrix <- tmp4[,c(tmp01, tmp02, tmp03)]; survdiff 함수에서 필요한 3개의 값들만을 모은 후에
bstr.n <- nrow(bstr.matrix)
tmp1 <- matrix(nrow=bstr.k, ncol=1); p.value 의 분포를 확인하기 위하여 미리 값을 저장할 곳을 만들고
for (Y in 1:bstr.k){
bstr.order <- sample(c(1:bstr.n), replace=TRUE)
bstr.temp.matrix <- matrix(nrow=bstr.n, ncol=ncol(bstr.matrix)); bootstrapping sample 을 위한 빈 matrix 만들고
for (X in 1:bstr.n){bstr.temp.matrix[X,] <- bstr.matrix[bstr.order[X],]}
tmp2 <- survdiff(Surv(bstr.temp.matrix[,1], bstr.temp.matrix[,2], type=”right”) ~ bstr.temp.matrix[,3])
p.val <- 1 – pchisq(tmp2$chisq, length(tmp2$n) – 1)
tmp1[Y, 1] <- p.val
rm(bstr.order, bstr.temp.matrix, tmp2, p.val)
}
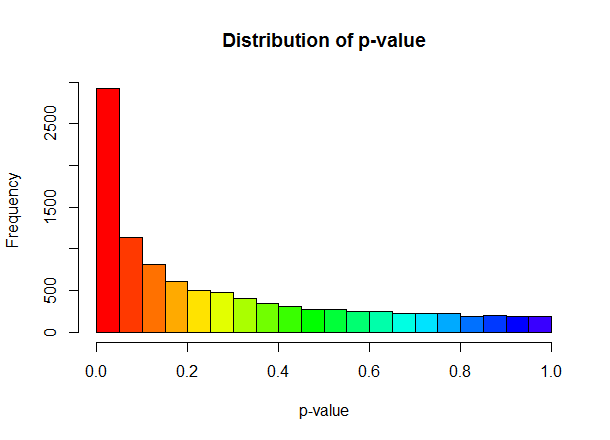
hist(tmp1[,1], breaks=20, freq=TRUE); Histogram
length(which(tmp1[,1] < 0.05))/bstr.k; 0.05 미만인 것들의 빈도

10,000번을 반복했을 경우, p-value 가 0.05 미만일 가능성은 30% 정도 된다.(붉은 색)
원자료만을 바탕으로 생존 분석을 시행하였을 때에는
통계적으로 의미있는 차이를 보여주지는 않았다.
하지만 bootstrapping 을 통하여 분석을 시행한 결과를 언급하면
조금은 더 그럴듯한 결론을 만들어 낼 수 있다.
즉, 나의 실험 결과를 바탕으로 모집단에서의 빈도를 추정하여 보았을 때
30% 정도는 통계적으로 유의한 결과를 보여준다.
뭔가 그럴듯한 결론을 이끌어 낼 수 있다는 점에서
이 통계기법은 조금은 더 깊게 알아볼만한 가치가 있는 것 같다.