최근의 일반적인 이미지 프로그램들은 색상을 저장할 때 RGB 순서대로 저장을 한다. 그런데 OpenCV에서 imread로 파일을 불러올 때에는 BGR 순서대로 불러오는 것 같다. 인터넷 검색을 해보면 초기에 카메라 업체들이 파일을 저장할 때 BGR를 이용했기 때문에 이런것 같다는 내용을 찾아볼 수 있다. 어제 염색 색상이 다르게 보이길래 모니터 색상이 문제인가 싶었는데, 그것치고는 너무 심하여 아마 이 순서에 따른 문제로 판단했다. cvtColor로 쉽게 변환할 수 있다.
보다 자세하게는 현미경 소견에서 관찰되는 개체를 인식할 수 있는가에 대한 것이다. 일단 고전적인 방법으로 접근하여 보았다. 인터넷 동호회의 정보를 바탕으로 모멘트(moments)에 대한 것을 검색하기 시작했고, 컨투어(contour)가 내가 원하는 기능이라는 것을 확인했다. 유채색을 고려하는 알고리즘은 못 찾았다. 그래서, 고전적인 방법으로 해보기로 했다. 이 방법에 있어서
가장 중요한 것은 분석 대상이 잘 구분되는 gray scale 이미지 변환이다.
OpenCV를 이용하여 시도해 보았던 방법은 RGB를 HSV로 변경하여 low와 high 범위내의 색상을 추출하는 것인데, 영 시원찮았다. CellProfiler를 이용하여 추출한 흑백 이미지를 이용했다. 이 경우에도 1-channel이 아니었기 때문에 변환시켜 준다.
Contours를 찾아주는 것은 아래와 같이 하면 된다. 2번째와 3번째는 contours를 설정하는 방법에 대한 것이다. 나는 findContours의 결과 중 첫 번째 Contours에 위치에 대한 정보만 있으면 된다. R과 Python의 중요한 차이점으로 처음이 1이 아닌 0이다.
Contours가 여러개 나오기 때문에 반복문을 이용해서 [i]가 있다. 이미지는 항상 똑바르게 서있거나 누워 있지 않기 때문에, 기울어진 직사각형으로 contours를 찾는 minAreaRect를 이용했다.
rect = cv2.minAreaRect(contours[i])
minAreaRect에서는 결과값이 3개가 나온다. 첫 번째 항목은 그림 파일에서 중앙 위치에 대한 것으로 (X, Y) 형태이다. 두 번째는 직사각형의 (폭, 넒이)이다. 가로 길쭉과 세로 길쭉 형태를 구분하지는 않는다. 세 번째는 기울어지는 정도이다. 시계 방향이면 양수, 시계 반대 방향이면 음수인 것 같다. 나의 경우에는 폭과 넓이만 필요해서 w와 h로 결과를 받았다.
(w, h) = rect
[1]
이렇게 찾은 contour가 올바른게 확인해 보려면 역시 봐야 한다. drawContours로 할 수 있다. 첫 번째는 이미지, 두번째는 좌표이다. minAreaRect로는 사각형을 그리는게 어려우니까 boxPoints로 그릴 수 있는 4개의 좌표로 변환한다. 픽셀에 소수점은 없으니까 NumPy를 이용하여 정수로 변환한다. 3번째는 첫 번째 contour를 뜻하는 0을 기술한다. 4번째는 색상이다. 추가 옵션으로 두께 같은 것이나, 모든 contour에 대한 것도 있다. 원하는 대로 잘 찾아졌는지 Pyplot으로 그려보면 된다.
최신 모델에 대한 공부는 안했으나, 현재 진행중인 논문에서 사용한 이미지 학습 모델 중 DenseNet-161이 가장 성능이 좋아서 이를 이용하여 후속 논문을 진행할 예정이다. 따라서, DenseNet을 좀 배워보기로 했다. DenseNet과 관련된 논문은 다음과 같다.
arXiv preprint arXiv:1608.06993
이 쪽은 결과를 우선 내는 것을 중요시 하기 때문에 피어 리뷰를 하지 않는다. 뭐, 성능 검증이 되면 그게 바로 리뷰하고 승인일텐데 굳이 그런 형식에 얽매일 분야는 아니라고 본다. 전문 지식이 없어 블로그(https://wingnim.tistory.com/39)에서 정리된 내용을 내가 필요한 부분만 다시 정리하여 보았다.
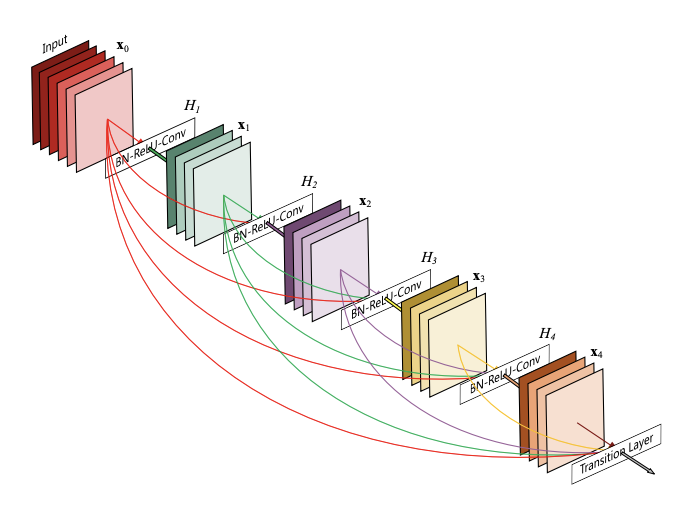
ResNet은 중간중간마다 이전의 결과를 받아오는 방법을 이용하였다면, DenseNet은 이전 정보들이 더 깊은 레이어까지 정보를 전달하는 방법이다. 그래서 네트웍이 조밀해(dense)진다.
https://pytorch.org/assets/images/densenet1.png
PyTorch에서 불러오는 방법은 다음과 같다. 애시당초 홈페이지에 당당하게 불러오는 방법이 안내되어 있다.
CNN에서 모델에 들어가는 이미지의 크기는 항상 일정해야 한다. 이미지의 크기가 작으면 요구하는 크기에 맞게 키워야 한다. 그 때 사용하는 방법이 사방을 0으로 둘러싸는 방법(zero-padding)과 비율에 맞게 키우는 방법이 있다. 이미지를 비율에 맞게 크게 하는 것은 어떤 방법에 따라서 임의의 값을 생성한다는 것이고 이를 보간법(interpolation)이라고 한다.
이 논문에서는 zero-padding과 interpolation 사이에 성능의 차이는 없다고 말하고 있다. 다만, zero-padding 된 부위가 계산 속도를 빠르게 해줄 수 있어서 더 좋지 않겠냐고 제시한다. 아직 이와 관련된 다른 이야기들은 찾기 못했다. 이와 같은 문제가 별로 상관이 없거나 아니면 작은 크기에 맞는 모델을 학습했다는 뜻이 아닐까 생각된다. 논문으로 쓸 만큼의 가치가 없는 것이 가장 적당한 이유가 아닐까 싶다.