최신 모델에 대한 공부는 안했으나, 현재 진행중인 논문에서 사용한 이미지 학습 모델 중 DenseNet-161이 가장 성능이 좋아서 이를 이용하여 후속 논문을 진행할 예정이다. 따라서, DenseNet을 좀 배워보기로 했다. DenseNet과 관련된 논문은 다음과 같다.
arXiv preprint arXiv:1608.06993
이 쪽은 결과를 우선 내는 것을 중요시 하기 때문에 피어 리뷰를 하지 않는다. 뭐, 성능 검증이 되면 그게 바로 리뷰하고 승인일텐데 굳이 그런 형식에 얽매일 분야는 아니라고 본다. 전문 지식이 없어 블로그(https://wingnim.tistory.com/39)에서 정리된 내용을 내가 필요한 부분만 다시 정리하여 보았다.
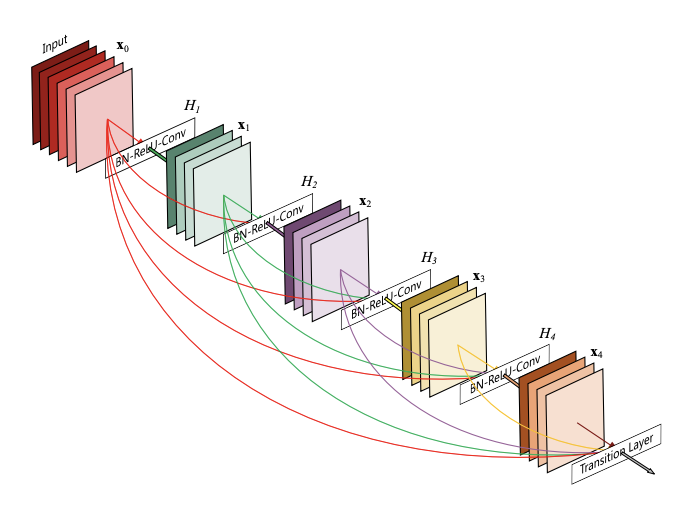
- ResNet은 중간중간마다 이전의 결과를 받아오는 방법을 이용하였다면, DenseNet은 이전 정보들이 더 깊은 레이어까지 정보를 전달하는 방법이다. 그래서 네트웍이 조밀해(dense)진다.
PyTorch에서 불러오는 방법은 다음과 같다. 애시당초 홈페이지에 당당하게 불러오는 방법이 안내되어 있다.
https://pytorch.org/hub/pytorch_vision_densenet/
무엇을 pretrained 했다는 것인지는 모르나, 알아 두어야 할 것은 다음이다.
- 3-channel RGB (3 x H x W)
- H와 W는 최소 224 pixels
- 값은 [0, 1]로 되도록 변환
- normalization 시행함.
from torchvision import transforms
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])이거는 이미지 변환과 관련된 부분인 것 같다. torchvision의 transforms를 이용한다. 따라서 자료를 찾아 보았다.
https://pytorch.org/docs/stable/torchvision/transforms.html
torchvision.transforms.Pad(padding, fill=0, padding_mode='constant')내가 필요한 것은 원하는 만큼 padding 하는 것이다. padding 항목 위치에 길이가 4인 tuple 형식으로 입력하면 왼쪽, 위, 오른쪽, 아래에 각각 채울 수 있다고 한다. fill=0은 기본값, constant는 그냥 채우는 것이다.